-
This site is deprecated and will be decommissioned shortly. For current information regarding HPC visit our new site: hpc.njit.edu
Difference between revisions of "WorkingHPCBaseline"

(Importing text file) |
(No difference)
|
Latest revision as of 16:36, 5 October 2020
Contents
Proposed High Performance Computing (HPC) Baseline Resource (HPC-BR)
Purpose of the HPC-BR
- Provide resources, including compute power, accommodation of big data (BD), software infrastructure, and high-capacity internal and external networking; provide support in running applications efficiently
- Provide a base level of infrastructure so that junior faculty can establish a record of scholarship, leading to external funding
- The resources now available are barely adequate for current researchers and coursework
- Provide the capability of supporting leading edge research
- Provide support in establishing collaborative research efforts with other institutions
- Maintain the HPC infrastructure at a level consistent with the needs of researchers and the maintenance of a competitive stance relative to NJIT's peers
- The resources now available put NJIT at a disadvantage in attracting promising researchers
- Provide an infrastructure suitable for educational purposes
- Provide researchers a more desirable option than self-provisioning HPC equipment
The HPC-BR would be one part of the strategy for providing HPC and BD resources:
- HPC-BR
- As needed, the capability to expand into:
- Regional and national HPC networks
- Cloud HPC providers
HPC Usage Statistics
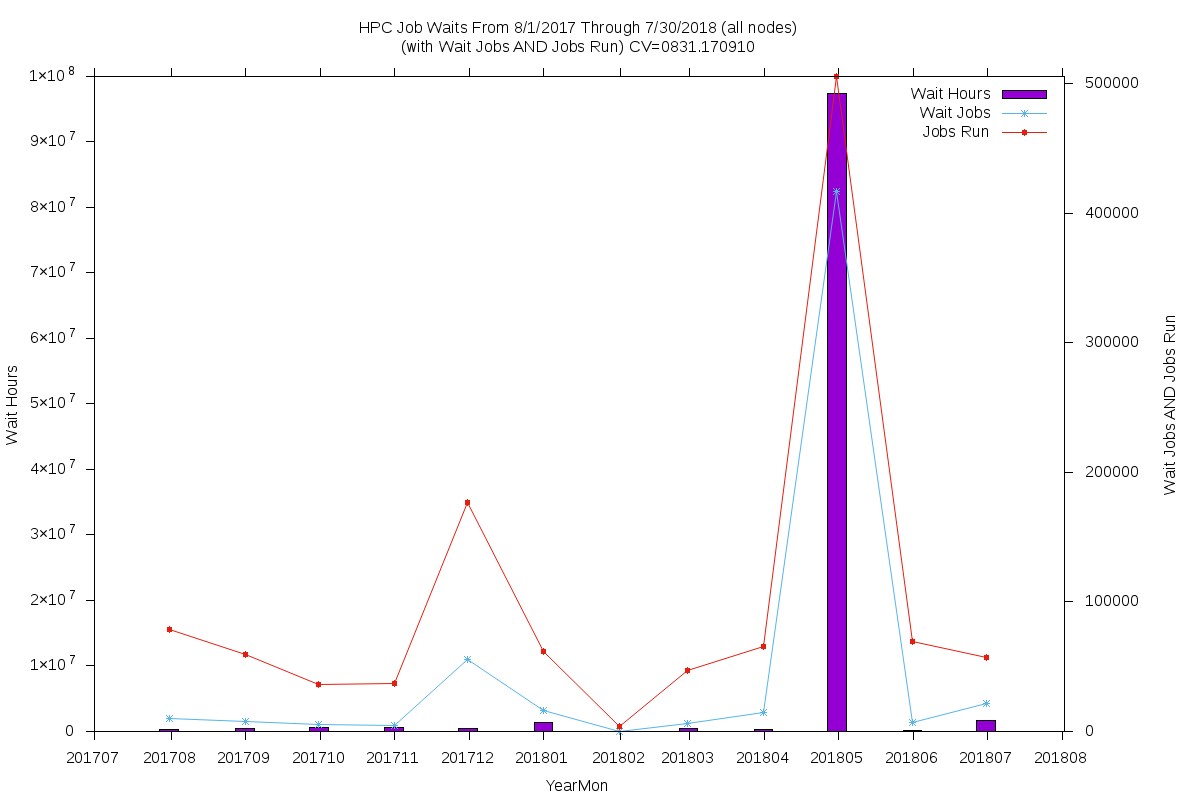
These charts show monthly queue (a set of nodes allocated for a specific purpose) wait times over a period of a year, July 2017 to August 2018. They demonstrate consistent over-subscription - i.e., jobs on nodes waiting until other jobs finish or give up enough resources so that the waiting job can be run.
All queues
- Public, reservers, and GPU queues
- Large spike in May 2018 hides other meaningful spikes in the following charts</li
{kind=link}
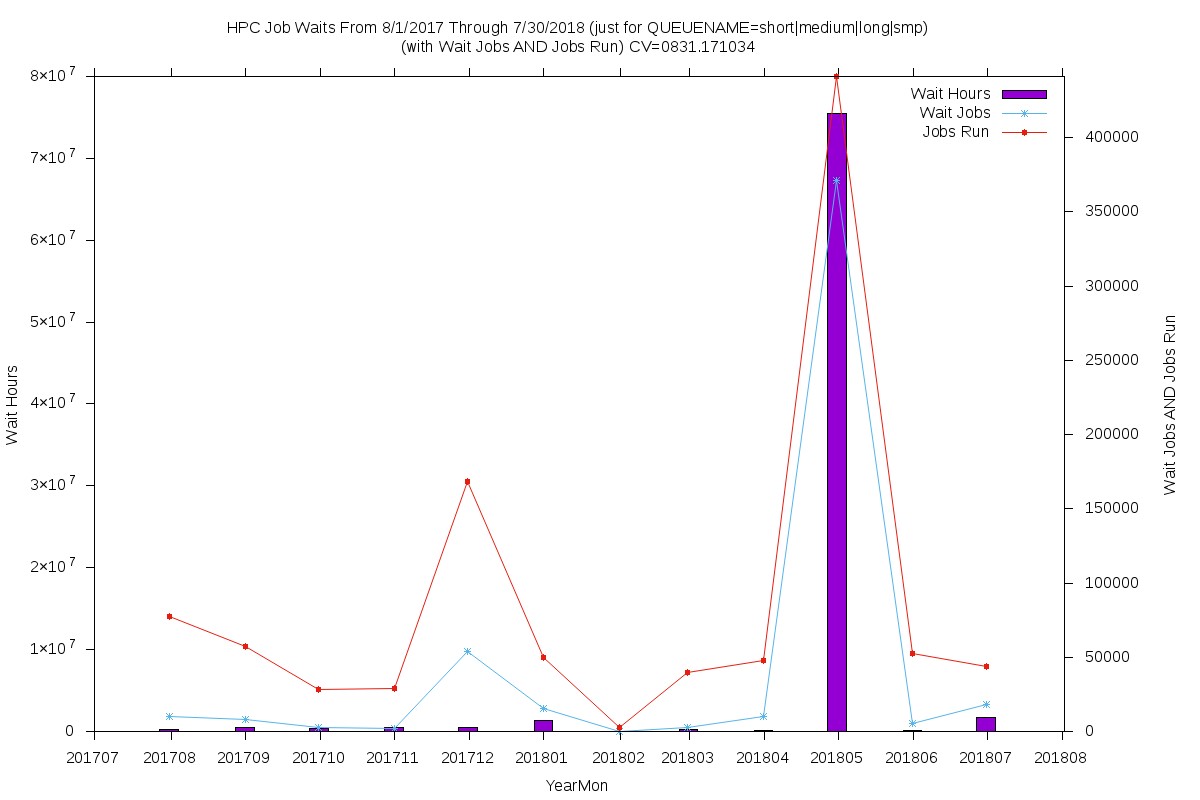
Public queue
- Used mostly by students for course work, and researchers who do not have access to a reserverd queue
- The May 2018 spike is most likely related to end-of-semester course work
{kind=link}
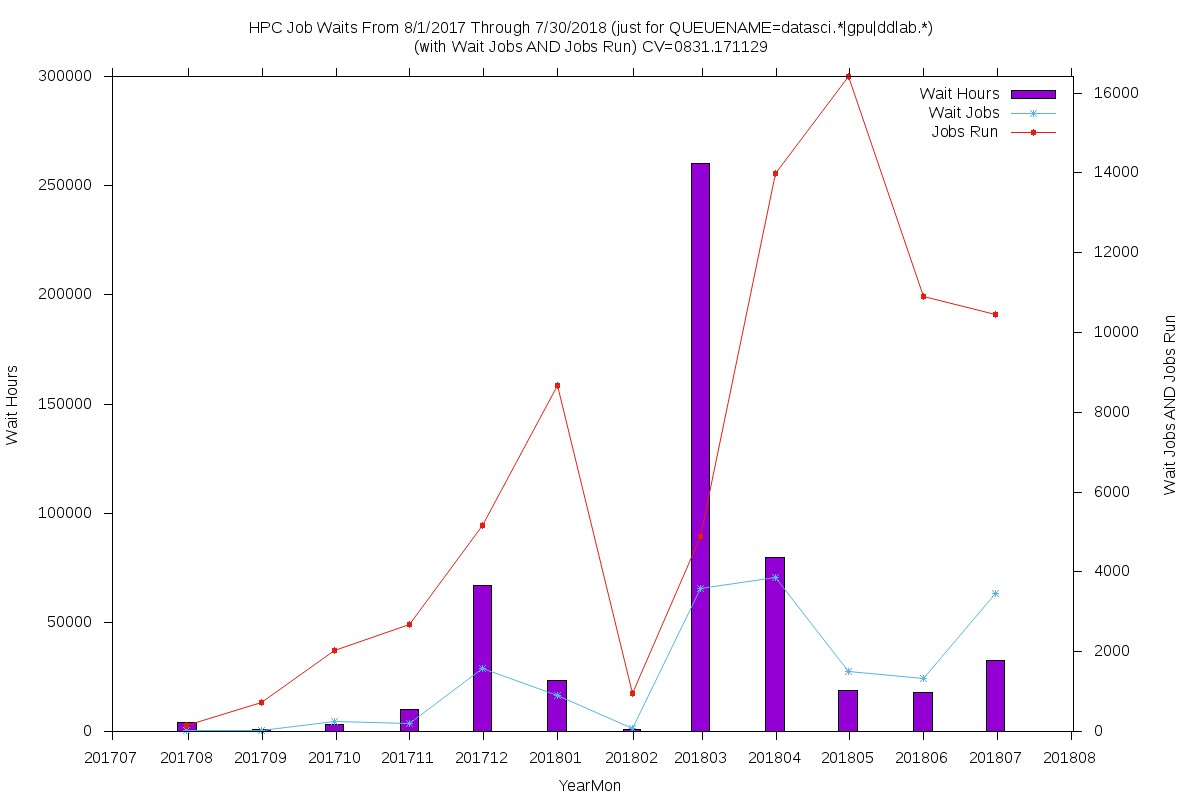
GPU queues
- This chart includes the single public GPU node
- Used mostly by researchers, but also some AI and machine learning courses
- Frequently loaned to researchers lacking GPU or SMP resources
- Differently-timed spikes suggest peak utilization unrelated to coursework
- These nodes are used for both GPU and SMP jobs because they have the
most CPU cores.
- If an SMP job needs all cores then GPU jobs must wait
- If one GPU job is running and an SMP job wants all cores, the SMP job must wait
- This makes it difficult to reliably use accounting data to assess GPU or SMP utilization
{kind=link}
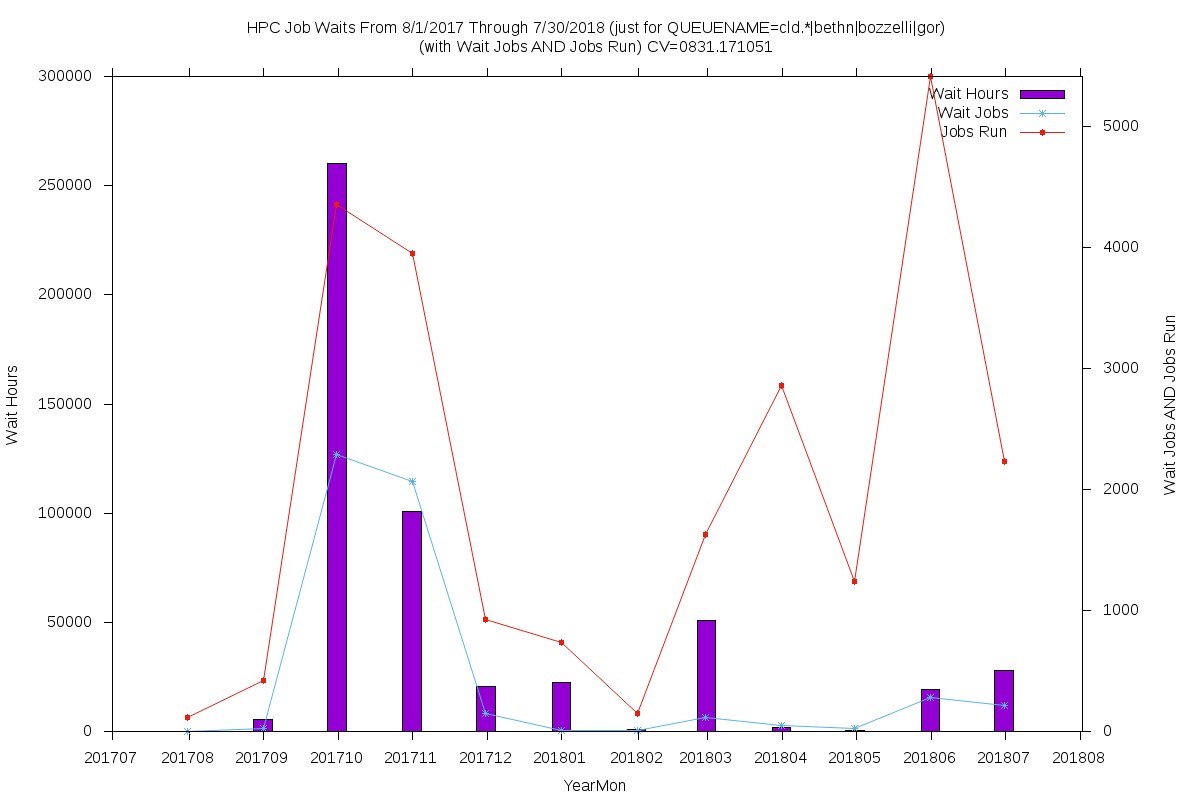
Reserved non-GPU queues
- Used by researchers who own the queues
- Occasionally loaned to reserachers that do not own the queue
- Demonstrates a third pattern of peak usage
Waits, Reserved non-GPU queues
{kind=link}
The HPC-BR proposal is similar to the existing HPC infrastructure in terms of number of cores, but with more RAM, much faster filesystem and much faster node interconnect. This will increase throughput; however the increased throughput might be offset by increasing HPC demand. Moving to OHPC with the SLURM scheduler will allow accurate usage metrics to be obtained. These usage metrics will be evaluated regularly to determine demand and the appropriate methods to address possible increases in demand.
SLURM will also allow unfunded researchers to automatically use reserved nodes when those nodes are not in use by their owners.
Spring 2018 HPC and BD Survey Extracts
Serial processing Of the 32 Kong respondents, 20 stated that a large or moderate increase in
CPU speed is needed; 13 stated that a large or moderate increase in RAM is needed. Both are addressed by the HPC-BR.
Serial Processing
Parallel processing Of the 35 Kong respondents, 21 stated that that a large or moderate increase in
CPU speed is needed; 18 stated that a a large or moderate increase in RAM is needed; 16 stated that a large or
moderate increase in node interconnect speed is needed. All three are addressed by the HPC-BR.
Parallel Processing
Parallel file system Of the 45 respondents, 14 rated a PFS as very or moderately importatnt. Hovever.
the backgrround information for PFS stated that it was used for temporary storage, when in fact it is now used for all
types of storage, due to recent innovations in Spectrum Scale. This information would likely have casued more respondents
to rank a PFS as very or moderately importaant, since lack of staorage is often cited as a major deficiency. The 1-PB PFS in the HPC-BR adreeses
this deficiency.
Parallel File System
Non-NJIT Resources The following deficiences are addressed by the HPC-BR: CPU cores too slow, Not enough RAM per core. Node
interconnect speed too slow, Not enough GPU cores. Read/write of temporay files too slow/Storage space inadwquate.
Non-NJIT Resources
HPC commentsHPC comments
High-speed node interconnect and parallel file system
Roles of inetrnal network and PFS
Configuration of HPC-BR
The Configuration of HPC-BR addresses all of the followung areas:
- Historical use of NJIT HPC resources
- The need for a high speed node interconnect and a parallel file system.
- The need for:
- High speed node interconnect. High speed node interconnect is available on the DMS cluster, Stheno, but on the much larger general-access cluster, Kong, it is available only to researhers who purchase it for their own use.
- Parallel file system (PFS). The current HPC resources have no PFS.
- Greatly expanded GPU resources
- Minimizing space, power, and HVAC requirements
| Category | Sub-category | HPC Current - General Access | HPC Current - Private Access (Kong dedicated nodes + Stheno) |
HPC Proposed Baseline Resource (HPC-BR) |
Notes |
|---|---|---|---|---|---|
| CPU | |||||
| Nodes | 240 | 54 | 20 | ||
| Cores | 1,896 | 816 | 1,760 | ||
| RAM, TB | 10.5 | 8.6 | 15 | ||
| CPU with GPU | |||||
| Nodes | 2 | 14 | 5 | ||
| GPU cores | 9,984 | 72,320 | 204,800 | About 1000 Kong cores are permanently out of service due to hardware failure | |
| CPU cores | 40 | 204 | 240 | GPU nodes are often used for CPU SMP jobs due to the large number of cores on the node | |
| RAM, TB | 0.25 | 2.7 | 3.8 | ||
| CPU TFLOPS | 15 | 8.5 | 15 | ||
| Node interconnect | 1 Gb/sec | Kong: 13 of 10Gb/sec, 12 of 56 Gb/sec, remainder 1Gb/sec; Stheno: 40 Gb/sec |
100 Gb/sec | ||
| Parallel file system | None | None | 1,000 TB | Traditionally used for temporary files, PFS are now used for all kinds of storage. Researcher requests for storage are routinely 10 to 20TB, compared to 50 to 100GB two to three years ago | |
| Racks | 9 | 3 | 6 | ||
| Power requirement, KWatts | 83 | 85 | 147 | HPC-BR spec is for BeeGFS; spec for IBM Spectrum Scale is not known | |
| Cost | - | = | $1.6M |
Cost comparisons
- Cost of AWS HPC-BR comparable resource
- A purpose of the HPC-BR is to provide adequate resources for courses using HPC. In particular,
the HPC-BR is configured to adequately support the needs of the CS Data Science Master's program, which
uses GPUs extensively.
GPU cost analysis using AWS for Deep Learning course (U. Roshan, CS): GPU Cost Analysis
This analysis shows an AWS cost of $90,688/year for the current MS enrollment of 77. By contrast, the GPU enhancement proposed for the Data Science program in July 2018 would have cost about $90K, and would have had a useful life of at least three years.